クロス集計 (CROSSTABS)
【用途】(順序尺度を含む)質的変数の関連の分析 !!社会調査の分析の主役!!
【データ】出力例1~4、7は、國學院大学 経済学部「アンケート調査」 2014年度「コンビニ、漫画、ディズニー・リゾート、俳優と旅行についての調査」【を開く】の性別(設問40)のおにぎりが最も好きなコンビニチェーン(設問4)のクロス集計であり、設問4の質問文は「あなたが最も好きなおにぎりはどのチェーンのものですか。ひとつだけ選んでください」である。出力例2も同調査の、性別(設問40)のスイーツが最も好きなコンビニチェーン(設問5)のクロス集計であり、設問5の質問文は「あなたが最も好きなおにぎりはどのチェーンのものですか。ひとつだけ選んでください」である。設問4と設問5ともに、もとの回答選択肢は 「1_ココストア」、「2_サークルKサンクス」、「3_スリーエフ」、「4_セイコーマート」、「5_セブン-イレブン」、「6_デイリーヤマザキ」、「7_ファミリーマート」、「8_ポプラ」、「9_ミニストップ」、「10_ローソン」、「11_こだわりはない」、「12_コンビニで(設問4ならば)おにぎり(設問5ならば)スイーツは買わない」の12カテゴリーの単一回答であり、これらをともに回答が少なかった回答選択肢を「その他のチェーン」に統合し、回答が多かった「セブン-イレブン」、「ファミリーマート」、「ローソン」、「こだわりはない」、「コンビニで(設問4ならば)おにぎり(設問5ならば)スイーツは買わない」の5カテゴリーに再編し、「コンビニで(設問4ならば)おにぎり(設問5ならば)スイーツは買わない」は欠損値とした。
【手順】
- メニューバーの[分析]を選択し、ドロップダウン・リストから[記述統計]を、その右のドロップダウン・リストから[クロス集計表]を選択する。

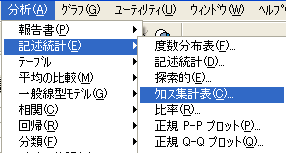
28版 15版 図1 クロス集計表の選択 - [クロス集計表]ダイアログ・ボックスで、左側の変数リストから行(表側)変数を選択(クリックまたはドラッグ)し、右向きの、16版以降ならば矢印、15版以前ならば三角形のボタンをクリックすると、右側上段の行変数ボックスに表示される。なお、複数の変数を一度に選択したい時には、集計する最初の変数を左クリックし、スクロールバーを使用するなどの方法で移動し、集計する最後の変数をシフトキーを押しながら左クリックして選択する。
- 左側の変数リストから列(表頭)変数を選択(クリックまたはドラッグ)し、(この図では変数を選択した後なので左向きになっているが)右向きの、16版以降ならば矢印、15版以前ならば三角形のボタンをクリックすると、右側中段の列変数ボックスに表示される。
※「アンケート調査」の履修者には、レイアウト上の問題で独立変数もしくはクロスの軸を列(表頭)変数として選択することを推奨する。 - ここで[OK]ボタンをクリックしてしまうと、%が出力されない!!
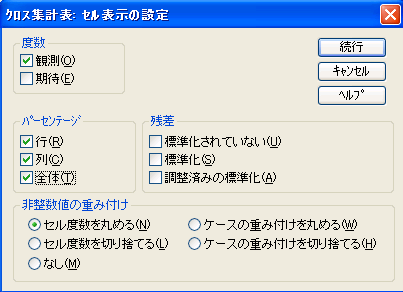
ので、16版以降ならば上から2番目の、15版以前ならば下段中の、[セル]ボタンをクリックして、[クロス集計表:セルの表示の設定]チェックボックスを開く。


28版 15版 図2 クロス集計表のダイアログ・ボックス - 行(表側)変数が独立変数またはクロスの軸である場合には、左下のパーセンテージの[行]ををチェックし、
- 列(表頭)変数が独立変数またはクロスの軸である場合には、[列]をチェックし、
- 行変数と列変数とのどちらが独立変数でどちらが従属変数なのか区別がない(相互関係などの)場合には、[行]と[列]の両方をチェックし、
※この例では列変数だけチェックすれば十分であるが出力例での説明の都合上、[行][列][合計](15版では[全体])のすべてをチェックした。 - [続行]ボタンをクリックする。

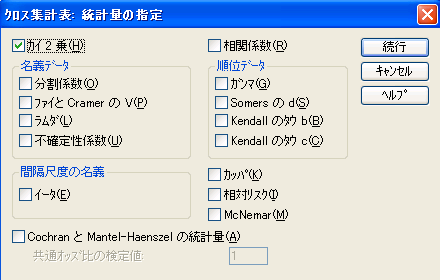
28版 15版 図3 クロス集計表:セルの表示の設定のチェックボックス - せっかくSPSSを使うのだからχ二乗値検定【を開く】やその他の統計量が必要な時には、図2 16版以降ならば1番上の、15版以前ならば下段左の[統計ボタン]をクリックし、
- 開かれた[クロス集計表:統計量の指定]チェックボックスの必要な統計量(この例では、χ二乗値検定だけ)の項目をクリックし、[続行]ボタンをクリックする。

28版 15版 図4 クロス集計表:統計量の指定のチェックボックス - [クロス集計表]ダイアログ・ボックスの[OK]ボタンをクリックする。
【デフォルトの出力】セル内の度数、周辺分布
【出力例1:性別(設問40)のおにぎりが最も好きなコンビニチェーン(設問4)(2014年度)のクロス集計表】
- この出力例は、(前述したように、)図2で表側( 行) 変数におにぎりが最も好きなコンビニチェーン(設問4)、表頭(列)変数に性別(設問40)を選択したクロス集計結果である。
- (前述したように、)図3の[クロス集計表:セルの表示の設定]でパーセンテージの[行][列][全体]のすべてをチェックした。
表側の好きなおにぎりのチェーン(設問4)は「セブン-イレブン」、表頭の性別(設問40)は「1_男性」のセルに注目して、SPSSの出力の文字色は黒だけであるが、3つの%を説明する都合、[行]は赤、[列]は青、[総和]は緑で表示した。各セル内には上から順に、
- (デフォルトの統計量である)度数がセル内の最上行に出力される:好きなおにぎりのチェーン(設問4)は「セブン-イレブン」、かつ、性別(設問40)は「1_男性」が127人いる。
- 行%:行(表側)変数の各行の周辺値を分母とする行%(69.4%)がセル内の上から2行目に出力される:好きなおにぎりのチェーン(設問4)は「セブン-イレブン」の合計183人のうち、「1_男性」が127人:69.4%=127人/183人*100、である。
- 列%:列(表頭)変数の各列の周辺値を分母とする列%(64.5%)がセル内の上から3行目に出力される:性別(設問40)が「1_男性」の計197人のうち、「セブン-イレブン」が127人:64.5%=127人/197人*100、である。
- 総和%:総和286人を分母とする総和%(44.4%)がセル内の最下行に出力される:「総和」計286人のうち、「セブン-イレブン」かつ「1_男性」が127人: 44.4%=127人/286人*100、である。
- 性別の好きなおにぎりのチェーンは、合計(=全体)で回答が多い順に、「セブン-イレブン」は男性が64.5%、女性が62.9%、「ファミリーマート」は男性が9.1%、女性が14.6%、男性が7.6%、女性が7.9%とほぼ同じぐらいであった。
表1 クロス集計の出力例1 (23版)
| 性別(設問40) | 合計 | ||||
| 1_男性 | 2_女性 | ||||
| 好きなおにぎりのチェーン(設問4) | セブン-イレブン | 度数 | 127 | 56 | 183 |
| 好きなおにぎりのチェーン(設問4) の % | 69.4% | 30.6% | 100.0% | ||
| 性別(設問40) の % | 64.5% | 62.9% | 64.0% | ||
| 総和の % | 44.4% | 19.6% | 64.0% | ||
| ファミリーマート | 度数 | 18 | 13 | 31 | |
| 好きなおにぎりのチェーン(設問4) の % | 58.1% | 41.9% | 100.0% | ||
| 性別(設問40) の % | 9.1% | 14.6% | 10.8% | ||
| 総和の % | 6.3% | 4.5% | 10.8% | ||
| ローソン | 度数 | 15 | 7 | 22 | |
| 好きなおにぎりのチェーン(設問4) の % | 68.2% | 31.8% | 100.0% | ||
| 性別(設問40) の % | 7.6% | 7.9% | 7.7% | ||
| 総和の % | 5.2% | 2.4% | 7.7% | ||
| その他のチェーン | 度数 | 6 | 0 | 6 | |
| 好きなおにぎりのチェーン(設問4) の % | 100.0% | 0.0% | 100.0% | ||
| 性別(設問40) の % | 3.0% | 0.0% | 2.1% | ||
| 総和の % | 2.1% | 0.0% | 2.1% | ||
| こだわりはない | 度数 | 31 | 13 | 44 | |
| 好きなおにぎりのチェーン(設問4) の % | 70.5% | 29.5% | 100.0% | ||
| 性別(設問40) の % | 15.7% | 14.6% | 15.4% | ||
| 総和の % | 10.8% | 4.5% | 15.4% | ||
| 合計 | 度数 | 197 | 89 | 286 | |
| 好きなおにぎりのチェーン(設問4) の % | 68.9% | 31.1% | 100.0% | ||
| 性別(設問40) の % | 100.0% | 100.0% | 100.0% | ||
| 総和の % | 68.9% | 31.1% | 100.0% | ||